
Luego de muchas iteraciones de nombres y conceptos, hoy el concepto de Ingeniería de Datos engloba las herramientas conceptuales y prácticas que hacen posible tomar los datos de dónde estén y traerlos hacia un espacio de trabajo, transformarlos y emplearlos para la toma de decisiones.
La ingesta de datos se encarga de extraer los datos y para eso usa diferentes enfoques, por ejemplo:
- usar interfaces que se proporcionan para eso (por ejemplo, para obtener datos públicos de clima o financieros, o para que los datos de un sistema interno de una empresa puedan ser usados en otro sistema propio o “amigo”);
- escudriñar pacientemente con programas creados para eso, los códigos HTML de las páginas web de interés.
Una vez que los datos están en “tierra conocida” como resultado de la ingesta, la transformación de los datos permite prepararlos para que sean más útiles. Entre estas acciones suelen estar:
- limpiarlos (tratar datos faltantes o erróneos, por ejemplo, entender que “Espana” en un listado de países se refiere a España o “completar” el país de un cliente de cual no se tiene ese dato a partir de saber que su teléfono empieza con 53 y asumir a partir de ahí que es cubano);
- estandarizarlos (por ejemplo, usar una forma única para referirse a un país que a veces se nombra como Reino Unido, otras como Inglaterra o por siglas como UK, lo cual incluye decisiones y asunciones porque no siempre se refieren a lo mismo);
- consolidarlos (por ejemplo, obteniendo las ganancias mensuales sumando los valores diarios, o el crecimiento mensual de la temperatura restando los valores entre las dos fechas de inicios de mes).
Pasando por estas acciones, se llega a datos que aportan alguna utilidad, este es el momento en que pueden usarse para ayudar en el proceso de toma de decisiones. Llegado a este punto, herramientas como Grafana vienen a cerrar el ciclo de los datos siendo una de las herramientas líderes según Gartner para este tipo de tareas (ver https://grafana.com/blog/2025/07/10/grafana-labs-named-a-leader-again-in-the-2025-gartner-magic-quadrant-for-observability-platforms/?utm_source=grafana_news&utm_medium=rss).
La flexibilidad de Grafana para la visualización crece con numerosas extensiones que existen para ella, que permiten poner a disposición del análisis de datos muchos gráficos tan interesantes como los siguientes (ver más en https://volkovlabs.io/plugins/business-charts/examples/). Los gráficos disponibles van desde conocidos gráficos de líneas, barras, radar y otros, hasta algunos mucho más avanzados. Por ejemplo, este gráfico muestra las relaciones entre los personajes de la novela “Los Miserables” empleando líneas que los vinculan y colores que los diferencian a estos según determinados criterios. Lo interesante es que, cambiando la semántica subyacente, una empresa puede emplearlo para mostrar cómo se vinculan las palabras que usan los clientes para referirse a los productos de una empresa y los colores pueden diferenciar si la palabra se usa principalmente en comentarios positivos o negativos.
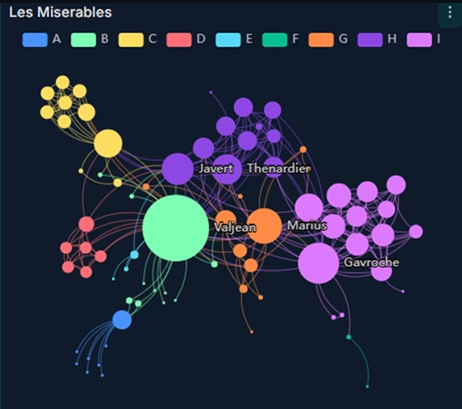
Desde la perspectiva de la Analítica de Datos (ver el “qué” y el “ahora”) las potencialidades de Grafana son notables, lo cual le ha dado esa posición de liderazgo. Sin embargo, al igual que pasa con muchos de sus competidores, Grafana no cuenta con gráficos específicos para visualizar modelos de aprendizaje automático (en inglés: machine learning). Con esto, se podría no solo ver el “qué” y el “ahora” sino también el “por qué” y el “futuro”, pasando de una perspectiva de Analítica de Datos a una de Ciencia de Datos.
En trabajos recientes, se ha iniciado la ruta encaminada a dotar a Grafana de herramientas para poder visualizar estos modelos (https://rci.cujae.edu.cu/index.php/rci/article/view/944 , https://publicaciones.uci.cu/index.php/serie/article/view/1817). Por ejemplo, usando comentarios de los clientes sobre un determinado servicio y obteniendo de cada comentario su longitud, las palabras usadas y la valoración general o polaridad del mismo (positivo, negativo, neutro), se pueden mostrar gráficos como los siguientes:
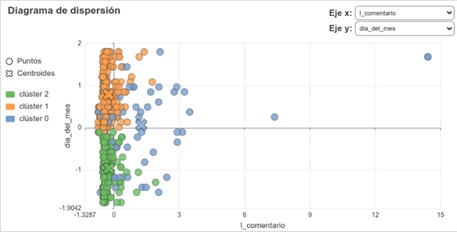
El primero, muestra el resultado de un agrupamiento de los comentarios en 3 grupos (identificados con colores diferentes), a partir de encontrar semejanzas entre ellos según las características de los comentarios, por ejemplo, aquellos que usan palabras similares. En la figura, cada grupo de comentarios tiene un centroide (señalado por una cruz) que indica la media de todo el grupo, teniendo selectores que permiten escoger las diferentes dimensiones o características en que se visualizan los datos. Por ejemplo, aquí se ve que el grupo naranja está por encima del grupo verde en el eje y, mientras que el grupo azul está más disperso siendo el único que toma valores altos en el ejemplo x.
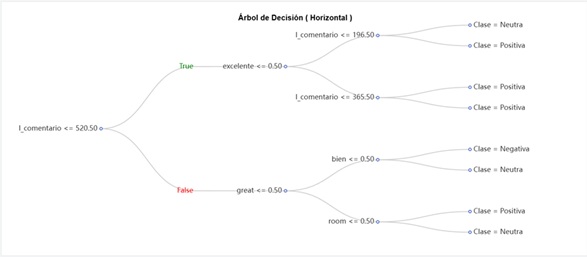
También se puede visualizar un árbol de decisión inferido de los datos. En este ejemplo, el árbol expresa qué condiciones del comentario hacen que este sea positivo o negativo. Por ejemplo, en este caso, los comentarios largos que no usan las palabras “great” o “bien” son negativos, mientras que aquellos que sí usan “great” pero no usan “room” son positivos.
Esto abre mucho más las potencialidades de aprovechar el ciclo completo de los datos para aprovecharlos para la toma de decisiones. Por ejemplo, un agrupamiento puede mostrarle a una empresa los productos que tienen patrones similares de ventas (en este caso, los atributos de cada producto podrían ser las ventas mensuales) o meses que tienen similares patrones de quejas (en este caso, los atributos de cada producto podrían ser las cantidades de quejas de cada tipo).
Por su parte, un árbol de decisión permitiría a una empresa predecir cómo serán las ventas de un producto dentro de varios meses, por ejemplo, llegando a reglas como “si el producto en el segundo mes duplica las ventas, pero en el tercer mes estas caen, entonces dentro de un año tendrá muy pocas ventas”.
En próximas entregas, se presentarán ejemplos concretos de herramientas que aplican estos conceptos para hacer que los datos puedan aportar mucho más a la toma de decisiones.